From Months to Minutes: Accelerating Your AI Pipeline
Skip the manual data cleaning and move straight to innovation with Python-compatible historians that allow you to build digital twins and anomaly detection directly on your live data stream.
2/19/20262 min read
Why Python-Ready Data Pipelines are the Secret to Industrial AI Success
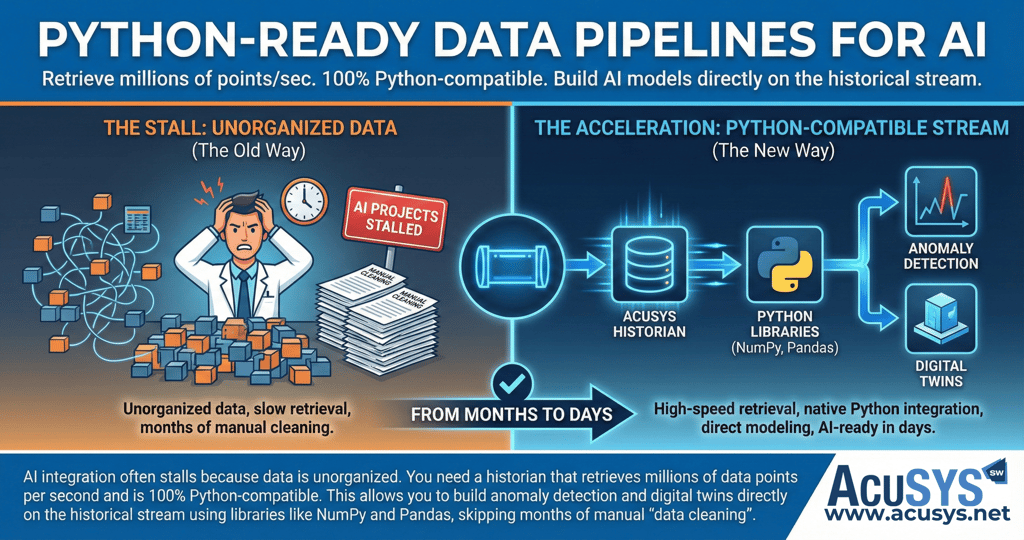
The ambition to create smarter manufacturing operations through Artificial Intelligence is a strategic imperative, yet a persistent gap exists between ambition and reality. AI integration often stalls because industrial data is unorganized, trapped in proprietary formats, or stored in siloed databases that do not align with modern tools. This leads to the "AI Paradox": facilities produce terabytes of data daily but spend months on manual "data cleaning" instead of delivering outcomes.
The Bottleneck: High-Speed Retrieval
Traditional SQL databases are often inefficient for high-speed time-series data and lack the features needed to easily manipulate that data for machine learning. To prepare for AI, you need a high-performance historian like CCi Historian, which is capable of storing over one million tags and retrieving history at a sustained rate of 70 million values per second. This speed is typically 10 to 1,000 times faster than many well-known competitors, providing the "big data" foundation required for real-time insights.
The Solution: 100% Python Compatibility
A modern data pipeline must be "Python-ready" to close the gap between the shop floor and advanced analytics. CCi Historian is 100% Python-compatible, offering direct APIs to the industry's most powerful scientific libraries:
NumPy and SciPy: For high-performance scientific computing and analysis.
Pandas: For seamless data manipulation and cleansing without manual intervention.
Scikit-learn: For building and deploying machine learning models directly on the historical data stream.
Building the Industrial Digital Twin
By integrating these Python libraries directly into the data pipeline, engineers can automate complex tasks like real-time anomaly detection and predictive maintenance modelling. This architecture enables the creation of "Digital Twins"—real-time digital models of production lines that allow teams to "fast-forward, rewind, or pause" through production sequences to diagnose the root cause of a crash or validate model accuracy.
The Bottom Line: Speed to Value
Facilities that implement standardized data architectures using protocols like OPC UA and MQTT, backed by Python-ready historians, achieve a 60–80% reduction in AI deployment time. By skipping months of manual data cleaning and reconciliation, your team can focus on what matters: transforming raw data into the actionable intelligence that defines a high-performance manufacturing operation.
Copyright 2026 AcuSYS Software Solutions (Pty) Ltd. All Rights Reserved.